Production AI · Live jeremyveleber.com
Full-stack portfolio with LangGraph-orchestrated RAG chat — reference architecture for production LLM integration
 jeremyveleber.com
jeremyveleber.com
jeremyveleber.com
Full-stack portfolio with LangGraph-orchestrated RAG chat — reference architecture for production LLM integration
Problem
Modern portfolios need to demonstrate full-stack AI/LLM capabilities in production — not just toy demos, but real orchestration patterns, RAG integration, and deployment considerations.
Solution
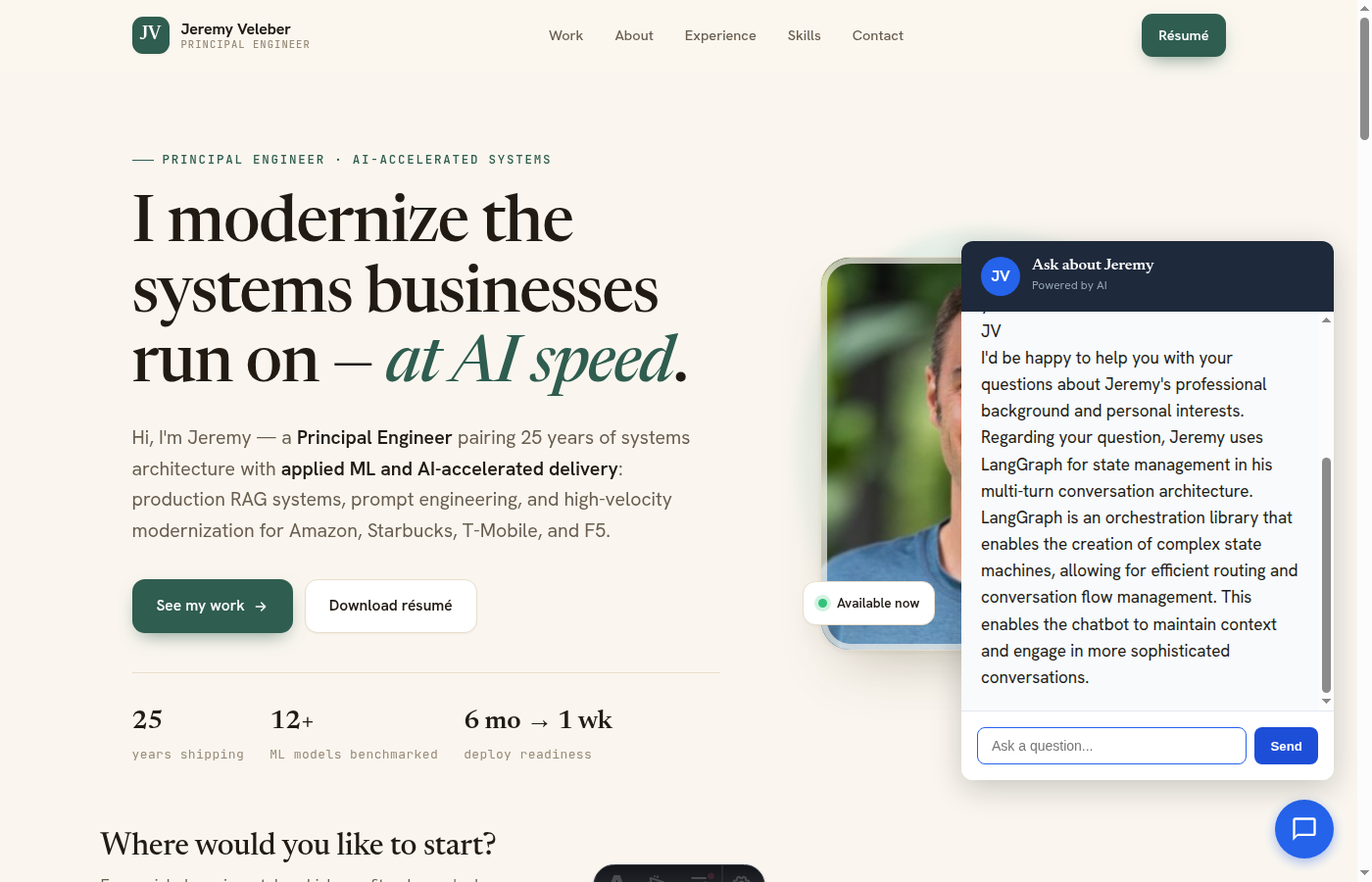
- LangGraph state orchestration — conditional routing through PII detection → intent classification → specialized response nodes (clarification, comparison, RAG).
- RAG knowledge base — ChromaDB vector store with sentence-transformer embeddings, ingests personal knowledge for context-aware responses.
- Production-grade backend — FastAPI with rate limiting, CORS, health checks, deployed to GCP Cloud Run.
- Smart keep-alive — Frontend detects user activity and sends pings only when active. Prevents cold starts without wasting resources.
- Frontend integration — Astro SSG with interactive ChatWidget, seamless API calls to LangGraph backend.
Stack
LangGraph for state orchestration, LangChain for RAG chains, ChromaDB persistent vector store with GCS backing, FastAPI async backend, Groq LLM inference, Astro SSG frontend, Docker on GCP Cloud Run with automated CI/CD.
Outcome
Production reference architecture demonstrating LangGraph conditional routing, RAG integration patterns, and Cloud Run deployment optimizations. Showcases orchestration beyond simple LLM calls — multi-node decision graphs, persistent vector storage, and real-world latency mitigation.